
In this digital era, understanding the distinctions between FPGA, GPU, CPU, and ASIC is crucial. Our aim is to demystify these technologies and guide you through the intriguing world of these computing giants. Let’s dive in and explore the differences between FPGA, GPU, CPU, and ASIC to empower your tech knowledge.
1. Overview of CPU
The primary chip in your computer, phone, television, etc. known as the Central Processing Unit (CPU) is in charge of dispersing instructions throughout the motherboard’s electronic components. The most adaptable of the chips we’re discussing is the CPU, which is referred to as the “brain” of the computer. It will use more power and do some tasks slower than the more specialized CPUs as a result of its versatility, though.

CPU Architecture
Of the computing architectures discussed here, the CPU, which is more than half a century old, is the best known and most prevalent. the CPU architecture is sometimes referred to as a scalar architecture because it is designed to handle serial instructions efficiently. CPUs have been optimized through many available techniques to increase instruction-level parallelism (ILP) so that serial programs can be executed as quickly as possible.
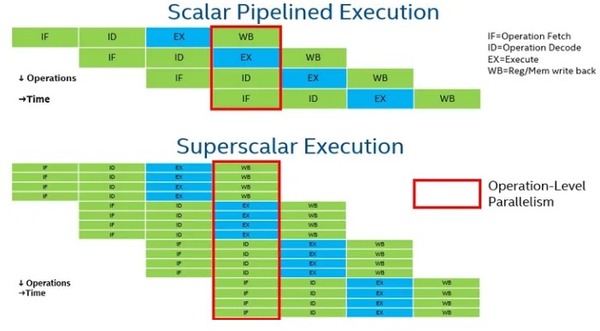
When there are no dependencies, scalar pipelined CPU cores can execute instructions divided into several levels at a rate of up to one instruction per clock cycle (IPC). To improve performance, modern CPU cores are multithreaded superscalar processors with sophisticated mechanisms for finding instruction-level parallelism and executing multiple disordered instructions per clock cycle. With typically ten times the IPC speed of scalar processors, they retrieve numerous instructions at once, identify the dependency graph between them, employ sophisticated branch prediction techniques, and then execute those instructions in parallel.

There are many advantages to using the CPU for computation compared to offloading the CPU to a coprocessor such as a GPU or FPGA. First, waiting time is reduced with minimal data transfer overhead because there is no need to offload data. High performance can be easily achieved on modern CPUs because high-frequency CPUs are tuned to optimize scalar execution and because most software algorithms are inherently serial. For the part of the algorithm that can be vector parallelized, modern CPUs support single instruction, multiple data (SIMD) instructions such as Intel® Advanced Vector Extension 512. Thus, the CPU is suitable for a wide range of workloads. Even for heavily parallel workloads, CPUs outperform gas pedals for algorithms with high branching dispersion or high instruction-level parallelism, especially when the data size to computation ratio is high.
2. Overview of GPU
The General-Purpose Graphics Processing Unit (GPU) is a form of graphics processing unit that uses a graphics processing unit to compute general-purpose computing activities that would typically be handled by the central processor unit. GPUs are general-purpose processors, just as CPUs. However, since GPUs have more cores, they can execute more tasks concurrently and can perform floating-point calculations more effectively.

GPU Architecture
GPUs are processors composed of massively parallel, smaller, more specialized cores that are typically more powerful than those in high-performance CPUs. GPU architectures are optimized for the total throughput of all cores, thereby de-emphasizing the latency and performance of individual threads. GPU architectures efficiently process vector data (arrays of numbers), often referred to as vector architectures. More silicon space is dedicated to computation and less to caching and control. As a result, GPU hardware explores less instruction-level parallelism and relies on software-provided parallelism to achieve performance and efficiency. GPUs are ordered processors and do not support complex branch prediction. Instead, they have an excessive number of arithmetic logic units (ALUs) and deep pipelines. Performance is achieved through multi-threaded execution of large independent data, which spreads the cost of simpler control and smaller caches.
GPUs use a single instruction multi-threaded (SIMT) execution model where multiple threads are used together with SIMD. In the SIMT model, multiple threads (work items or sequences of SIMD channel operations) are processed in a lock-step fashion within the same SIMD instruction stream. Multiple SIMD instruction streams are mapped to a single execution unit (EU), and the GPU EU can context-switch between these SIMD instruction streams when one stream is stopped. (or sequence of SIMD channel operations) are processed in lock-step within the same SIMD instruction stream. Multiple SIMD instruction streams are mapped to a single execution unit (EU), and the GPU EU can context-switch between these SIMD instruction streams when a stream is stopped. (or sequence of SIMD channel operations) are processed in lock-step within the same SIMD instruction stream. Multiple SIMD instruction streams are mapped to a single execution unit (EU), and the GPU EU can context-switch between these SIMD instruction streams when a stream is stopped.
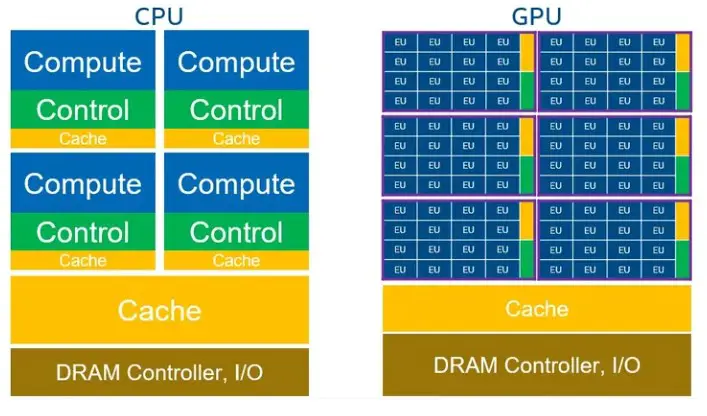
The diagram above shows the difference between a CPU and a GPU. EU is the basic unit of processing on a GPU. Each EU can handle multiple SIMD instruction streams. GPUs have more cores/ EUs in the same silicon space than CPUs. GPUs are organized in a hierarchical structure. Multiple EUs are grouped together to form compute units with shared local memory and synchronization mechanisms (aka sub slicing or streaming multiprocessors, outlined in purple).
3. Overview of FPGA
Although it is also a silicon-based semiconductor, the Field Programmable Gate Array (FPGA) is built from a matrix of customizable logic blocks (CLBs) that are interconnected by programmable interconnects. An FPGA can be programmed to carry out particular functions or applications. programming in C/C++ and hardware languages is supported, and it has a good energy efficiency ratio and low latency. However, a function must be reprogrammed each time it has to be modified.

FPGA Architecture
Unlike fixed-architecture CPUs and GPUs that can be programmed in software, FPGAs are reconfigurable and their computational engines are defined by the user. When software is written for FPGAs, the compiled instructions become hardware components that are spatially arranged on the FPGA architecture and that can all be executed in parallel. For this reason, FPGA architectures are sometimes referred to as spatial architectures.
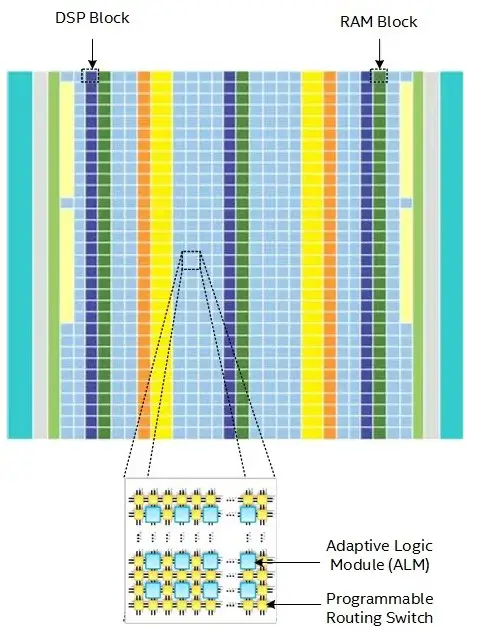
FPGAs are arrays of large numbers of small processing units containing up to millions of programmable 1-bit adaptive logic blocks (each of which can work like a one-bit ALU), up to tens of thousands of configurable memory blocks, and thousands of mathematical engines called digital signal processing (DSP) blocks that support variable-precision floating-point and fixed-point operations. All of these resources are connected through a grid of programmable wires that can be activated as needed.
When software is “executed” on an FPGA, it is executed in a different sense than when compiled and assembled instructions are executed on the CPU and GPU. Instead, data flows through a custom deep pipeline on the FPGA that matches the operations expressed in the software. Because the data flow pipeline hardware matches the software, control overhead is eliminated, resulting in improved performance and efficiency. With CPUs and GPUs, the instruction level is pipelined and new instructions begin execution at each clock cycle. With FPGAs, operations are pipelined so that a new instruction stream that operates on different data starts executing every clock cycle.
Although pipelined parallelization is the primary form of FPGA parallelization, it can be used in combination with other types of parallelization. For example, data parallelism (SIMD), task parallelism (multiple pipelines), and superscalar execution (multiple independent instructions executed in parallel) can be used in conjunction with pipeline parallelism to achieve optimal performance.
4. Overview of ASIC
A silicon chip type called a “Application Specific Integrated Circuit” (ASIC) is made for a particular logic function. It is a unique chip that implements a particular hardware function. Based on algorithm requirements, the ASIC chip’s computational capacity and effectiveness can be modified, however they cannot be altered.
ASIC chips are consequently tiny in size, power-efficient, and offer high specific computing capability. The application scope cannot be altered once it has been modified, and it is expensive to do so.
FPGA vs. GPU vs. CPU vs. ASIC Advantages
The advantages of CPU
- Out-of-order superscalar execution
- Complex controls can extract huge instruction-level parallelism
- Accurate branch prediction
- Automatic parallelism on sequential code
- Large number of supported instructions
- Shorter latency compared to offload acceleration
- Sequential code execution simplifies the development process
The advantages of GPU
- Massively parallel, up to thousands of small, efficient SIMD cores/ EUs
- Efficient execution of data-parallel code
- High dynamic random access memory (DRAM) bandwidth
The advantages of CPU
- Efficiency: The data processing pipeline is fully tuned to software requirements. No need for control units, instruction fetch units, register write-backs and other execution overhead.
- Custom instructions: Instructions that are not supported by the CPU / GPU itself can be easily implemented and efficiently executed on the FPGA (e.g., bit manipulation).
- Data dependencies across parallel work can be addressed without causing pipeline stalls.
- Flexibility: FPGAs are able to be rearranged to support various functions and data kinds, including unusual data types.
- Customized on-chip memory topology has been tuned to the algorithm: Large bandwidth on-chip memory is built in to accommodate access patterns to minimize or eliminate stuttering.
- Rich I/O: FPGA cores can interact directly with a variety of networks, memory, and custom interfaces and protocols, enabling low-deterministic latency solutions.
The advantages of ASIC
- The design cost is very low for any high volume. It turns out that implementing ASIC designs in larger quantities is less expensive than implementing designs using FPGA.
- Faster than FPGA is ASIC. The potential for speed improvements is immense.
- Analog and mixed-signal designs can be implemented in ASIC. In FPGA, this is typically not feasible.
- ASIC allows for flexible design.
- ASIC can be tuned to use as little power as possible, which extends the life of batteries.
- DET is introduced into ASIC. DET is not utilized in FGPGA.
CPU vs. GPU vs. FPGA vs. ASIC
| Computing Performance: | |
| CPU | The CPU’s core, which follows the von Neumann design, houses both data and program storage. The number of CPU cores affects both serial and parallel computing capability. As a result, the CPU’s computing capacity is limited. |
| GPU | The von Neumann architecture is also utilized by the GPU. ALU compute units, on the other hand, take up more than 80% of the GPU chip area, compared to less than 20% of the CPU space. As a result, the GPU’s computing performance has improved, particularly in terms of its capacity to do floating-point calculations. |
| FPGA | The FPGA employs a technique that does not share instructions or memory. In order to increase computing efficiency, hardware programming is used to build software algorithms. As a result, processing efficiency is significantly greater than that of the CPU and GPU. The computing workload is relatively low due to the no-memory approach, and the CPU needs to work together to complete some difficult computations. |
| ASIC | CPLD and FPGA are currently combined to create ASIC chips. As a result, they offer comparable computational performance to FPGA. It is clear that an ASIC is an FPGA chip whose algorithm logic has been constructed in accordance with a particular scenario. |
| Power Consumption: | |
| CPU | The CPU must use a variety of instruction sets and store data in the cache when handling a lot of sophisticated logic processes. The CPU will therefore have a huge physical footprint and significant power requirements. |
| GPU | The GPU still needs to access the cache for processing, just like the CPU. The GPU is larger and uses more power than the CPU since it has more cores, a higher capacity for parallel computation, and a faster speed. In most cases, a separate fan must be installed on the GPU to ensure heat dissipation. |
| FPGA | The FPGA chip is tiny and uses less power since it lacks instructions and does not require a shared memory system. |
| ASIC | The ASIC is similar to the FPGA in that it does not require a shared memory architecture and simply uses a single logic algorithm. As a result, the ASIC uses less energy. |
| Latency: | |
| CPU | During calculation, the CPU must call upon numerous instruction sets and cache data. The delay is hence high. |
| GPU | The GPU must invoke numerous instruction sets and cache data during computation, just like the CPU. However, the latency of the GPU is lower than that of the CPU because it has a faster cache access speed. |
| FPGA | When carrying out operations, the FPGA is not required to use the instruction set or cache data. Consequently, the FPGA has far higher latency than the CPU, by an order of magnitude. |
| ASIC | Similar to FPGAs, ASICs can perform operations without using the instruction set or a cache. Consequently, the FPGA has far higher latency than the CPU, by an order of magnitude. |
| Flexibility: | |
| CPU | The CPU has good versatility because it is set up to carry out broad computation. The most common type of processor is CPU. |
| GPU | GPUs are initially primarily utilized for graphics processing. With each each generation of GPUs, however, the ability to handle complicated logic computation has been added, so GPUs are no longer just for rendering graphics. The heterogeneous computing environment around today’s CPUs is established, mature, and flexible. |
| FPGA | FPGA is a type of chip that has been partially modified and needs to be built again for everyday use. FPGA has poor flexibility as a result. |
| ASIC | ASIC can be thought of as an FPGA chip on which logic algorithms have been constructed, as was previously indicated. ASIC is a specialized chip that can only be used in particular situations. ASIC is therefore not very flexible. |
Conclusion of CPU vs. GPU vs. FPGA vs. ASIC
- Overall, in terms of computing performance, CPU<GPU<FPGA≈ASIC.
- When we concern about the power consumption, ASIC<FPGA<CPU<GPU.
- In terms of flexibility, ASIC<FPGA<GPU≈CPU.
- When we consider about the latency, ASIC≈FPGA<GPU<CPU.
ASICs, or application-specific integrated circuits, are what give CPUs and GPUs their ability to specialize on one task and perform it effectively. While GPUs are made to process massively parallel workloads as quickly as possible with hundreds or even thousands of tiny cores, CPUs are made to perform the calculations necessary for general computing as quickly as possible using a small number of powerful cores.
A general-purpose integrated circuit called an FPGA is composed of numerous logic circuits that can be “wired up” in any way you like. A FPGA configured to be a CPU or GPU will always be slower than the actual CPU or GPU due to the lack of specialization. The FPGA, on the other hand, can be programmed with logic to do computation tasks for which neither CPUs nor GPUs are optimized. Your FPGA can be programmed to do a specific set of intricate calculations on a data input faster than a CPU.
The FPGA still has the advantage of being able to be reprogrammed if you need to undertake another task suitable for it, even though an ASIC could be created to perform these same exact workloads faster than the FPGA.
Related posts:
 Miniature cells and Batteries – Silver Oxide, Mercury and Lithium Cells
Miniature cells and Batteries – Silver Oxide, Mercury and Lithium Cells
 The Ultimate Guide to Computer Memory
The Ultimate Guide to Computer Memory
 Open Loop and Closed Loop Control System (4 Practical Examples Included)
Open Loop and Closed Loop Control System (4 Practical Examples Included)
 Beginner Friendly Kits That Most Newbie Used In Electronics
Beginner Friendly Kits That Most Newbie Used In Electronics
 Introduction to PCB Assembly Process
Introduction to PCB Assembly Process
 FPGA for Beginners: Definition, Landscape and Glossary
FPGA for Beginners: Definition, Landscape and Glossary
 How Can I Find Work in FPGA?
How Can I Find Work in FPGA?
 How to Create Engaging Embedded System Projects for Engineering Students
How to Create Engaging Embedded System Projects for Engineering Students
 Thermistor Sensor: A Comprehensive Guide
Thermistor Sensor: A Comprehensive Guide
 How EBAC is Enhancing Microelectronics Resilience
How EBAC is Enhancing Microelectronics Resilience