
The implementation of some self-testing capabilities in an embedded design is worthwhile unless available memory is completely exhausted.
Although modern electronics are amazingly reliable, they are still susceptible to failure. Failures in embedded systems can be broadly divided into four categories:
- CPU
- Peripheral
- Memory
- Software errors
If a CPU fails, it tends to be a hard failure. There is no possibility for self-testing in this system. Partial failure of a CPU is very unlikely. When there are multiple cores in a system, it is good practice to assign one core as “master” so that it can monitor the system integrity.

Peripherals can fail in a variety of ways, but many of them are device/application specific. When a device fails to respond to its address, the trap occurs; it is essential to include a trap handler to handle this fault. Otherwise, communications devices commonly include a “loopback” mode that enables testing of transmission and reception and associated interrupts.
Memory failures can happen at any time. This failure may be transient – for example, a single bit being flipped by a passing cosmic ray. Such a fault is generally not detectable and may result in a software crash. Therefore, it is essential to accommodate crash recovery. There could be a hard failure if the address response is not received, or if bits are stuck at 0 or 1. A trap handler deals with the former, but the latter requires some specific testing. Comprehensive memory testing can only be done on device start-up. A Moving Ones test is effective.
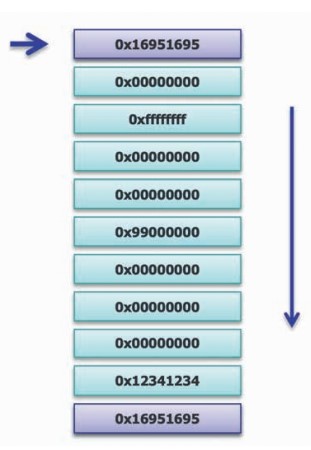
While the device is operating, pattern testing can be performed on individual bytes or words which may reveal certain types of failures.
In modern devices, software is the most complex component. Even though software does not wear out, its complexity can result in faults that are difficult to detect during development. Good, defensive coding techniques can help anticipate some problems.
In general, there are two types of software errors:
- data corruption
- code looping.
Data corruption can be caused by pointer misusage, which is hard to detect or prevent, but it can also be as a result overflow of a data structure, like an array or the stack. The insertion of “guard words” can assist with the detection of overflow before any damage is caused.
Code looping can be addressed by careful design – precautions like timeouts on waiting for devices – or some kind of watchdog facility (in hardware or software) that traps unresponsive code.
Related posts:
 Miniature cells and Batteries – Silver Oxide, Mercury and Lithium Cells
Miniature cells and Batteries – Silver Oxide, Mercury and Lithium Cells
 Open Loop and Closed Loop Control System (4 Practical Examples Included)
Open Loop and Closed Loop Control System (4 Practical Examples Included)
 Beginner Friendly Kits That Most Newbie Used In Electronics
Beginner Friendly Kits That Most Newbie Used In Electronics
 Introduction to PCB Assembly Process
Introduction to PCB Assembly Process
 FPGA for Beginners: Definition, Landscape and Glossary
FPGA for Beginners: Definition, Landscape and Glossary
 How Can I Find Work in FPGA?
How Can I Find Work in FPGA?
 How to Create Engaging Embedded System Projects for Engineering Students
How to Create Engaging Embedded System Projects for Engineering Students
 Thermistor Sensor: A Comprehensive Guide
Thermistor Sensor: A Comprehensive Guide
 How EBAC is Enhancing Microelectronics Resilience
How EBAC is Enhancing Microelectronics Resilience
 The Ultimate Guide to Computer Memory
The Ultimate Guide to Computer Memory